FFT-method expert vailidity
How to recognise fake online stores
If there is a lack of reliable data on the occurrence of specific events or knowledge on the consequences of decisions, there is a problem of uncertainty. Better decisions can hardly be achieved through the trained use of statistics or their transparent communication. Instead, the central question is how individual consumers can reduce uncertainty in their decision-making situation. Two scenarios are central here:
How can uncertainty be reduced (quickly, practically) for everyday problems in which consumers are left to their own devices?
How can uncertainty be reduced (quickly, practically) for everyday problems for which an expert provides advice to the consumer?
Why is it difficult to provide decision support for problems of uncertainty?
Decision problems of uncertainty are characterised by a lack of reliable data. This effectively rules out the direct selection of the best decision option. The support consists of identifying key strategies to reduce uncertainty. What do I need to ask to reduce the choice of potential information or options? What do I need to look for? What do I need to consider to sort out inappropriate options that do not meet the minimum requirements?
In contrast to consumers, experts in a particular subject area are able to identify objective shortfalls in the standard of a decision problem on the basis of fewer heuristic features. With the help of an analysis of specific consumer decision situations, possible expert heuristics are distilled into decision trees. These summarize the experts' gut feeling based on their experiences and provide consumers with a robust expertise that enables them, similar to the expert, to separate the wheat from the chaff.
This is not only important for issues where consumers are left to their own devices. Potential decision heuristics can also be combined in decision trees for consulting situations: Here it is a matter of asking the consultant the most important questions in order to be able to assess this situation robustly.
Fast-and-Frugal Trees (FFTs) are suitable decision trees that can be transparent, comprehensible to consumers and of high quality at the same time. These FFTs represent a sequence of features to be examined (Martignon et al., 2008). There is always only one branch (stop) or one arrives at the next test feature, but there are no further branches (see example below). This distinguishes the FFTs from the usual decision trees. Only the last feature in the chain has two branches.
It has been shown that FFTs enable fast and reliable decisions in various decision situations under uncertainty, e.g. in psychiatry, anaesthesiology, but also in the financial world (Aikman et al., 2014; Green & Mehr, 1997; Jenny et al., 2013). FFTs can be presented both digitally (e.g. app, website) and analogously to consumers (e.g. on posters or in brochures) in the form of a graphically illustrated, simple tree structure. This makes them an evidence-based instrument for decision support that is easy to implement. In the RisikoAtlas project it was developed and implemented for the first time for everyday consumer practice. The use of FFTs is also helpful because their application trains skills. The use of FFTs facilitates the internalisation of key characteristics for problems and stimulates critical thinking.
The order of features in an FFT is critical and must be determined in advance. There are both manual and more complex approaches using machine learning methods. Once statistically determined, this combination of features allows consumers to robustly classify decision options (e.g., whether an informed decision is possible) by independently examining those features.
How to construct a decision tree for a consumer problem - the FFT method of expert feature validity
A. What do you need?
For the evidence-based development of FFTs, all approaches (including the FFT method of expert-based feature validity) require base data consisting of three parts: Characteristics of the problem, problem cases and the respective case assessment.
Part 1 – Characteristics of the problem
First, it is necessary to clarify what the problem is and to define the concrete decision or assessment on which information should be provided. What is the decision tree supposed to deliver? Under this aspect, potential features are researched with the help of experts (e.g. workshops), colleagues, laypersons and specialist literature (trade journals, white papers, government reports and experience reports). Potential features are all those characteristics of the problem situation that could possibly be an indicator of a good or bad decision regarding the problem. It may also be worthwhile to include new features such as one's own assumptions or intuitions. A list of potential features should then have been established.
Each potential feature must be comprehensible and testable by a layperson. Ideally, the list should summarize similar features, especially if there are too many of them. It is fair to say that expert supported feature selection is the most important tool in advance, particularly when it comes to cost-effective development. After all, each additional feature requires more cases in order to allow robust development. As a rule of thumb, you can basically calculate 20 to 50 cases for each feature. Each case requires effort: Each case must be individually coded for all features and an assessment must be obtained. If you need support during this process, please consult the final report on the Risk Atlas project from July 2020 or contact us. Contact details can be found here.
Part 2 - Problem cases
Once you have made a selection of potential features, you need to find out how often and under what circumstances they occur in the real world. For this you collect material of typical decision situations, e.g. real purchase offers, videos of real consulting situations or real informational services.
If such case material of typical decision situations is not available, the FFT method of expert-based feature validity is the method of choice. Instead of the natural combinations of features in real cases, all possible virtual profiles of potential features are combined. Each combination of characteristics represents a profile and therefore a case.
Part 3 - Case assessment
For each case in your data basis, you must know or determine whether the target criterion is met or not. In the case of health information, for example, a positive assessment would be the target criterion if it enables an informed decision, otherwise it would be a negative assessment. Without this basis of already determined profiles, no model for future decision support is possible. One approach would be to test each profile or case, i.e. determine how it turned out. This involves considerable experimental effort. The alternative is the "view of the expert", which the model approach presented here was aimed at right from the start. Several independent experts evaluate each individual case (i.e. each profile, each combination of features) with regard to the objective of the development, e.g: "Does this health information allow an informed decision?
B. How do you proceed?
With the FFT method of expert-based feature validity, the significance of potential features is tested directly through expert assessments right from the start. Normalized frequency formats (... of every 100) are used to estimate the presence of each feature in relation to positive and negative target conditions. Resulting measures - positive predictive value, negative predictive value, false omission rate, false recognition rate, sensitivity, specificity, feature prevalence - are evaluated to minimize the number of target features. In addition, the frequency of occurrence of the target object is determined with experts. If you need assistance with the procedure, please consult the final report on the Risk Atlas project from July 2020 or contact us. Contact details can be found here.
This selection can be further reduced by testing laypersons on how successfully they evaluate the individual features. If you aim for six characteristics, this means that you always have to generate 2 to the power of 6 = 64 different combinations. Each feature can either be present or absent (or above or below a certain value limit). Since the experts also estimated feature prevalences, the associated probabilities can be used to estimate the profile frequency, i.e. how often certain combinations occur. This is crucial in order to weight the occurrence of the profiles in the data set realistically.
For all profiles, the expert evaluations are "collected" in a further study. Three experts receive every feature profile. This means that the expert's view can only be modeled using features familiar to them. This is qualitatively weaker than, for example, the FFT method of case-based feature validity.
The decision tree is modeled on the basis of these feature assessment profiles.
The pipeline for development can be summarized in a simplified illustration:

Modeling from tree development and cross-validation can be performed manually, but in the sense of effective modeling it is easier with the open source solution R. In addition to the FFTrees package (Phillips et al., 2017), you can also download a web solution by Evaldas Jablonskis and Uwe Czienskowski from http://www.adaptivetoolbox.net/Library/Trees/TreesHome#/. If you need assistance with this, please consult the final report on the Risk Atlas project from July 2020 or contact us. Contact details can be found here.
A Fast-and-Frugal Tree (FFT) is modeled using the portion of cases selected as training data; often 33% or 50% of cases. This FFT has a certain quality in terms of tracking down the target feature (assessment). This means it will miss cases in the real world and cause false alarms in others. To quantify this quality, either a statistical cross-validation can be performed (the determined decision tree is applied on randomly repeated cases; test data cases), or it can be applied once to a collection of cases with assessments that were put aside before modeling. Alternatively, a completely new sample of cases with feature encodings and ratings (out-of-sample) can be collected to which the decision tree is applied (additional effort).
Which quality is sufficient depends very much on the types of errors and the costs associated with the error. Finally, the model must be tested in practice with laypersons. Here a randomised controlled study is useful in which the decision intentions of consumers who are given the decision tree are compared with those who have nothing or a standard information sheet. If you need assistance with quality or evaluation, please consult the final report of the Risk Atlas project from July 2020 or contact us. Contact details can be found here.
- Aikman, D., Galesic, M., Gigerenzer, G., Kapadia, S., Katsikopoulos, K. V., Kothiyal, A., ... & Neumann, T. (2014). Taking uncertainty seriously: Simplicity versus complexity in financial regulation. Bank of England Financial Stability Paper, 28.
- Green, L., & Mehr, D. R. (1997). What alters physicians' decisions to admit to the coronary care unit?. Journal of Family Practice, 45(3), 219–226.
- Jablonskis, E., & Czienskowski, U. (2017). Decision trees online. http://www.adaptivetoolbox.net/Library/Trees/TreesHome#/
- Jenny, M. A., Pachur, T., Williams, S. L., Becker, E., & Margraf, J. (2013). Simple rules for detecting depression. Journal of Applied Research in Memory and Cognition, 2(3), 149–157.
- Luan, S., Schooler, L. J., & Gigerenzer, G. (2011). A signal-detection analysis of fast-and-frugal trees. Psychological Review, 118(2), 316.
- Martignon, L., Katsikopoulos, K. V., & Woike, J. K. (2008). Categorization with limited resources: A family of simple heuristics. Journal of Mathematical Psychology, 52(6), 352–361.
If you would like to adopt a consumer topic from our website, you can do so in the following three ways:
- You are using a digital copy. Either you directly save an illustration or download our PDF, or you integrate the illustration via Link(a href) or iframe.
- You take your analogue copy and print out our PDF. The resolution and vector-based graphic is suitable for posters and brochures.
- You recommend the app and refer to the Risikokompass from the PlayStore and AppStore.
If you would like to develop your own model, please consult the final report on the RiskAtlas project from July 2020 or contact us. Contact details can be found here.
When using the instruments, please mention the funding agency, which is the German Federal Ministry of Justice and Consumer Protection, and the Harding Centre for Risk Literacy as the responsible developers.
Logos can be downladed here.
FFT-Methode Nutzer-Validität
FFT-Methode getesteter Merkmalsvalidität
Perhaps the following situation seems familiar to you: For weeks you have been looking for a particular pair of sneakers. The manufacturer's website says that the model is sold out. You also cannot find anything on other mail order sites that are familiar to you. But then you come across a retailer, who you have never heard of, but who is offering a photo of exactly that type of shoe you want so badly. In fact, it is even 100 euros cheaper than on manufacturer's site. How lucky you are! Or are you?
Many people fall for the phenomenon of fake online stores. The only goal of these stores is to deprive you of your money. You will never receive the goods - or at least not the type you have ordered. These scam stores are rarely recognizable at first glance. This is also due to the fact that these websites are designed in an increasingly professional way and look like real online stores. With our decision tree you can check whether a website is a potential scam.
When do I need this graphic?
If you are shopping online and are trying out a new online retailer that you presumably found through a Google search, then this decision tree is for you.
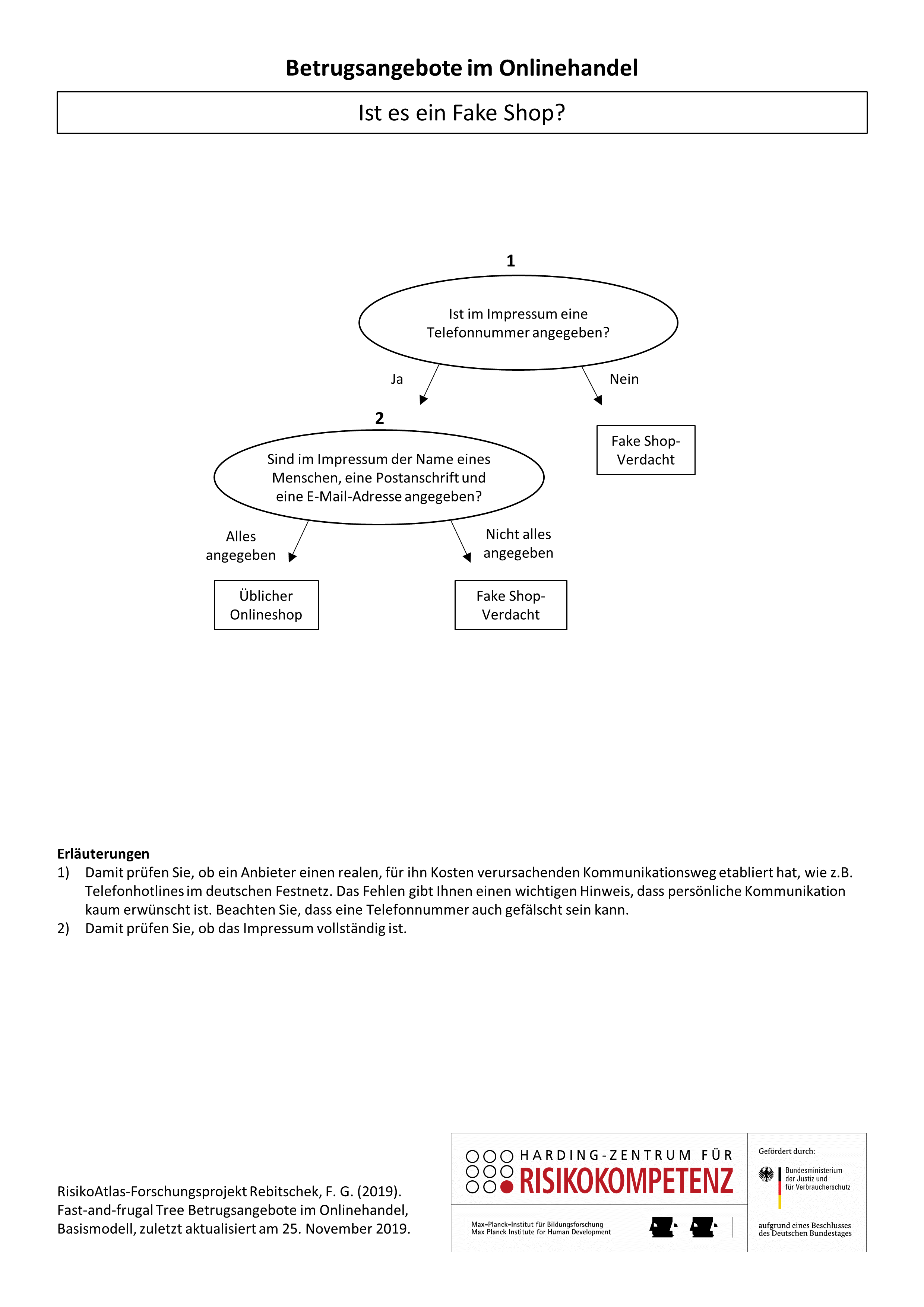
You can also check the store in question extensively. However, please note that no text and no checklist is ever perfect. With every additional feature that you check, the risk of an incorrect assessment of the text increases.
Further features are:
- There is a privacy policy (menu item privacy)
- The AGB refers to the legal right of withdrawal of 14 days from online purchase.
- General terms and conditions are available
- While entering your address for the order: does the website at the top of the browser start with "https"?
- Reference to the commercial register with corresponding number starting as follows "HR...". [not "Ust." = "sales tax"]
- A German-language presentation describing the company (retailer) is available.
- Contradiction in content between Internet address and type of product (e.g. shoes at a doctor's office) [NEGATIVE NOTE].
- Capitalization is wrong [NEGATIVE NOTE]
- Negative reports from customers can already be found on the first page with hits if you google the "store name" in quotation marks [NEGATIVE FEATURES].
- Only prepayment options offered as payment method [no payment by invoice, no direct debit] [NEGATIVE NOTE].
Where is the data coming from?
Cases – Which e-stores served as a basis?
255 German-langue online stores were compiled as the basis for training and test data sets. They were researched by experts from the Harding Center of Risk Literacy.
Target assessment – How was the status of scam stores and conventional online retailers determined?
Fake online stores were determined when they were reported as such (verbraucherschutz.de), or seal theft was reported by Trustedshops. For conventional online stores Trustedshops were randomly selected and the 100 top-selling online retaielrs were included.
Potential features – Which features were considered?
Based on various sources (computerbetrug.de, Europol, onlinewarnungen.de, originalo.de, sidnlabs.nl, verbraucherzentrale.de) 35 features were collected, 17 of which were considered as assessable by laypersons in principle.
Selection of features and modelling
The aim of the pre-selection of features was to limit the number of potential features for the prediction model. The feature selection was performed under two aspects: Testability through laypersons and statistical significance.
The FFTrees package was used for model identification (Phillips et al., 2017). The ifan algorithm was used to optimize for balanced accuracy.
What is the quality of the data?
The data set was randomly divided into training data sets (two thirds) and test data sets (one third).
The model is of the following quality:
A cross validation of the identified decision tree resulted in the following quality measures: balanced accuracy = 0.91; correct rejection of fake online stores (share of 57% in the test set) with 0.94. This means that 94 of 100 of such scam stores were detected by the decision tree.
The detection of conventional online stores was 0.88.
Potential for development
Continuous further development of the underlying training data due to changes in availability.
Empirical evaluation with consumers
All research results on the fundamentals and on the effectiveness of the RiskoAtlas tools in terms of competence enhancement, information search and risk communication will be published together with the project research report on 30 June 2020. If you are interested beforehand, please contact us directly (Felix Rebitschek, rebitschek@mpib-berlin.mpg.de).
Sources
• Computerbetrug.de (2017). Vorsicht beim Online-Shopping: So erkennen Sie einen Fake-Shop. Internet https://www.computerbetrug.de/2017/12/betrug-fake-shop-im-internet-erkennen-6562. Letzter Zugriff 25.11.2019.
• Europol (2019). How to detect fraudulent sites selling fakes. Internet
https://www.europol.europa.eu/activities-services/public-awareness-and-prevention-guides/how-to-detect-fraudulent-sites-selling-fakes. Letzter Zugriff 25.11.2019.
• Originalo.de (2019). Fake-Shops erkennen – Die wichtigsten Merkmale. Internet
https://www.originalo.de/info/fake-shops-sicher-erkennen. Letzter Zugriff 25.11.2019.
• Phillips, N. D., Neth, H., Woike, J. K., & Gaissmaier, W. (2017). FFTrees: A toolbox to create, visualize, and evaluate fast-and-frugal decision trees. Judgment and Decision making, 12(4), 344-368.
• van Spaandonk, C., Lastdrager, E., & Lansing, E. (2018). Fake webshops on .nl and .dk. Präsentation. https://www.sidnlabs.nl/downloads/presentations/jamboree2018-fakewebshops.pdf. Letzter Zugriff 15.03.2019.
• Verbraucherzentrale.de (2018). Abzocke online: Wie erkenne ich Fake-Shops im Internet? Internet https://www.verbraucherzentrale.de/wissen/digitale-welt/onlinehandel/abzocke-online-wie-erkenne-ich-fakeshops-im-internet-13166. Letzter Zugriff 25.11.2019.
• Wolf, P. (2019). Fakeshops erkennen: Online sicher einkaufen und gefälschte Onlineshops entlarven. Internet https://www.onlinewarnungen.de/ratgeber/fakeshops-erkennen-online-sicher-einkaufen. Letzter Zugriff 25.11.2019.
Last update: 27 November 2019.
Recognising fake product reviews
Informed telematics rate selection
Inkassobescheide prüfen
Vergleichsportale nutzen